18 Nov Something’s missing in the product leader’s toolkit
Our brains are being hacked by intelligent products. Sometimes this is a good thing — hacking us out of our lethargy, for example, to nudge us to exercise. For me, the fitness tracking app Strava has significantly upped my motivation for regular bike rides and runs.
Quite often, though, we are hacked in ways that don’t really benefit us. Much has been written about how social media platforms, powered by machine learning, feed us content intended to keep us engaged. Whether designed by the platform owners or not, this results in many users being drawn into unhealthy addiction cycles fed by emotionally-charged content unhinged from facts and reality.
Hacked for good – or ill?
Whether their effects turn out to be beneficial or deleterious, intelligent products by design are intended to maximize customer engagement. That is, they are designed to be sticky.
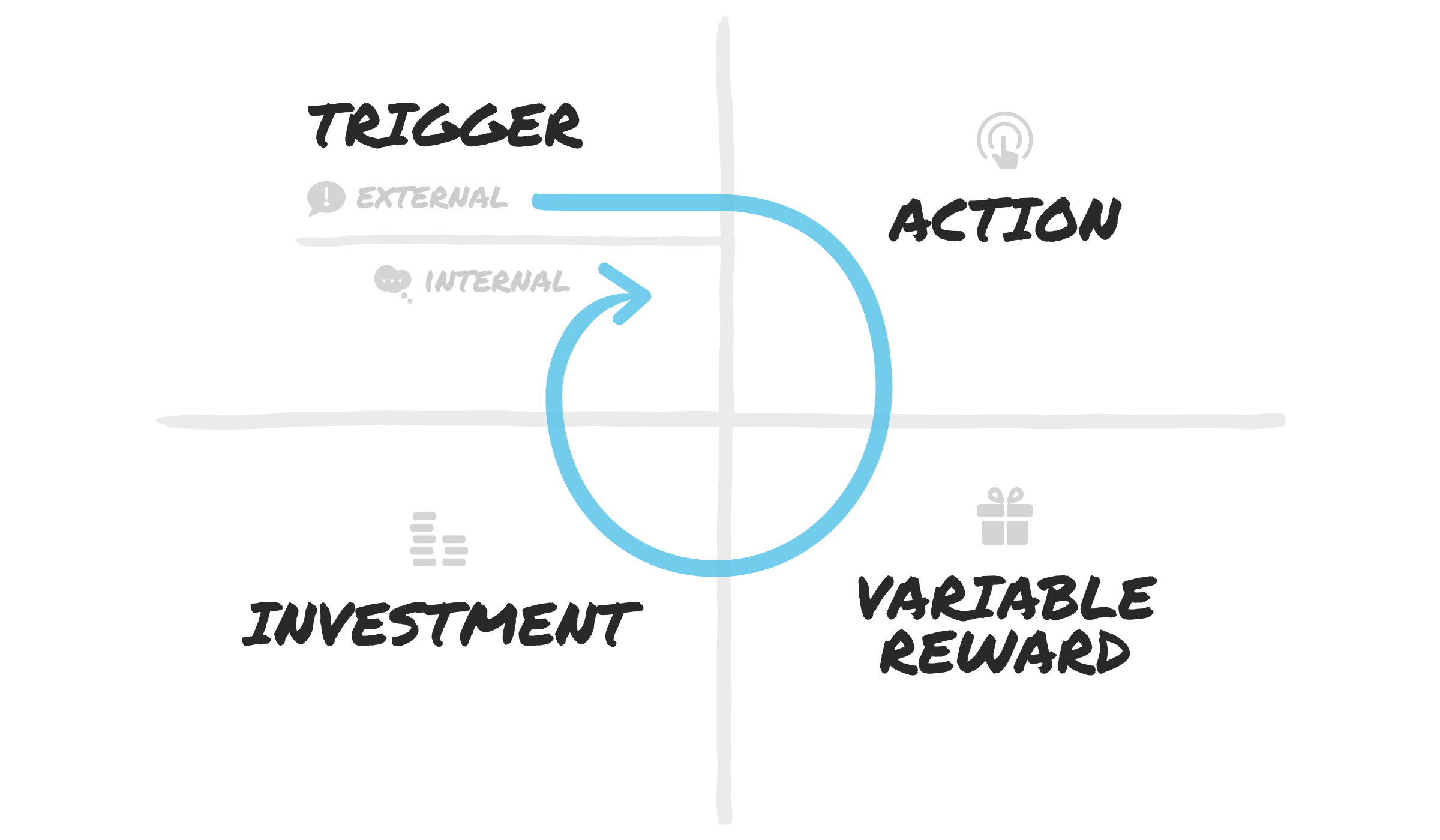
Fig 1: The Hook model, devised by Nir Eyal, offers a template for creating sticky products
They also contain within them the potential to help us think and reason more effectively, make better, more informed decisions, and solve challenging problems. Intelligent products can make us smarter.
Whether they do so in practice hinges less on their inherent intelligence. Rather, I would argue it is a function of how well those capabilities are designed (or not) to help humans solve meaningful and valuable problems.
What do we mean by an intelligent product? I have worked for over 20 years with organizations building data products to help people make complex, high-stakes decisions. Wrestling with massive amounts of big data (even before that was a thing), large companies have long struggled to get enterprise applications to surface up the kind of actionable insights that might support, say, a biotech company’s decision whether to invest $200 million in a research & development program.
Along the way we have seen a class of product evolve that is rapidly becoming ubiquitous. This kind of intelligent product —
- Is fed with data, often aggregated from disparate sources, that can give accurate depictions of particular situations
- Has analytics baked into it, so that the value of the data is enhanced via business logic and context for decision-making and problem-solving
- Leverages AI and machine learning, enabling it to adapt to evolving use scenarios, and provide predictive capabilities and personalization
- Incorporates, as appropriate, social capabilities to promote effective communication and collaboration.
2 sides of every intelligent product
Pretty much every data product you interact with now, in fact, is likely to be some form of intelligent product — the Uber app on your phone, Netflix, a weather app. Increasingly, tangible products contain embedded intelligence as well. Robot vacuum cleaners map the space of your house and find the most efficient dust-sweeping path.
The array of sensors deployed in your car gathers real-time data from key components, making it easier for you to drive safely and keep your vehicle maintained. We are all, however, familiar with the experience of — why the hell is it telling me that?? (a car’s dashboard reporting a flat tire that looks perfectly fine, weird movie recommendations….)
Do intelligent products benefit us? No doubt! Can they confound us and occasionally mess with our brains? Well, yeah!
The question I propose here is — how do we promote the beneficial aspects of these kinds of products while avoiding the negative ones?
To understand how to do that, we need to recognize that every intelligent product contains two sides — a data side, and a human side. Both sides present opportunities and challenges.
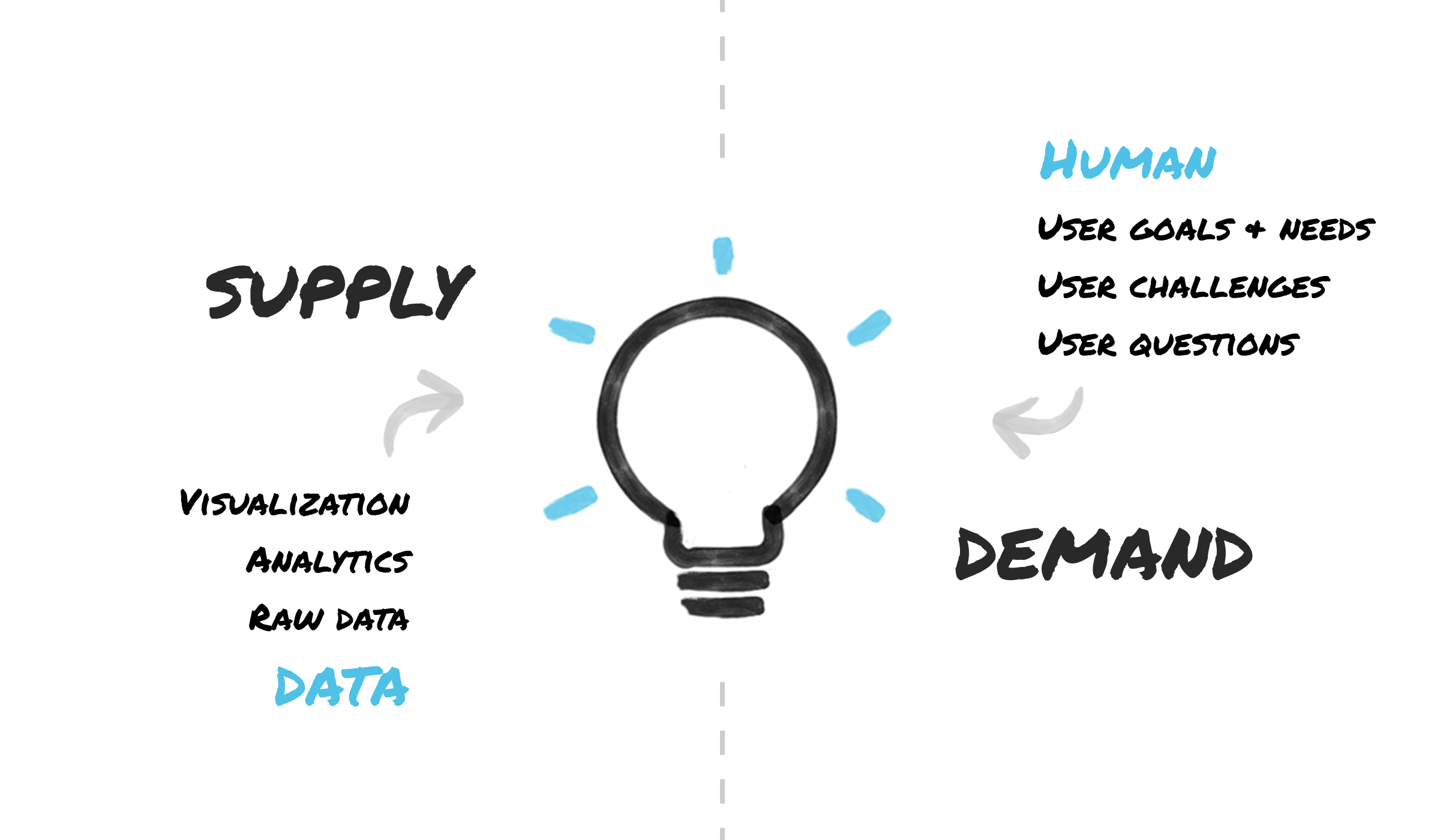
Fig 2: A supply-demand (or ‘push-pull’) model of data and cognition
Getting the data side of a product to work is often seen as a technical challenge, and to a large extent it is. Accessing, aggregating, cleaning, and harmonizing data that is drawn from multiple sources is not a trivial task. The left side of Fig 2 above, this supply side is traditionally the domain of analysts, data scientists and data architects. Making sure the appropriate data is available to a process in the timeframe needed can itself present engineering challenges, even beyond all the data science work likely involved.
But there is another aspect to this data supply side. The data and analytics may be said to represent a kind of ‘ intelligence potential.’ Although we may not say (yet) that information systems are capable of human-like reasoning, they contain within them elements of knowledge that can be put to intelligent use. They contain potential data stories.
How smart do we want our products to be?
Product designers are trained to ask how users are likely to benefit from all of the smart capabilities a product might offer. A product may be capable of making decisions on our behalf. But do we want those decisions made for us? How smart do we want our products to be? And smart in which ways? These demand-side questions begin to engage the human side — the right side of Fig 2.
Consider your intelligent automobile. It may be able to drive itself, but does that mean you want it to, on every trip to the grocery store? A sensor may be able to tell you which of its systems are not working properly, but does that mean you want a warning lamp to flash at you every time a component malfunctions?
What about things we think of as more personal decisions, like which house to buy, what college to attend, what job offer to accept, or even who is a compatible mate? To what extent are we willing to delegate such decisions to an intelligent machine? What distinguishes helpful intelligence from a Black Mirror scenario?
As has often happened historically, the engineering and technical capabilities of intelligent products seem to be ahead of the ability of those products to reliably connect with users in useful, meaningful and valuable ways. What human challenges do we see now?
- Interpretability of the data being displayed. Do I understand what it is telling me? Do I know what I am supposed to do with that information?
- Trust in the data- Why is it telling me that? Do I trust the data I’m seeing? Is it accurate? Where did it come from? Is it up to date with the latest information? How do I know a recommendation is based on the right data? How was a value calculated?
- Appropriateness and context of how the information is presented- Is it annoying me by telling me something at an inappropriate time? Is it spamming me with too much information? Did it fail to tell me something important when I needed to know it? Is it stressing me out?
- Agency and the balance of human vs machine decision-making — Is it offering me something I should be thinking about, or does it seem to be telling me what to do? Do I want the machine’s advice or recommendations at all? Should the machine make a decision for me, or provide me with helpful information so I can make a better decision myself? Does the machine seem to be behaving in my best interest? How well does it understand my goals? Does it really understand all the factors involved in my decision?
Updating the product ‘toolkit’
User experience practice has provided tremendous value to product teams by affording a ‘toolkit’ that enables a user-centric perspective to be captured (via discovery and research work) and integrated into the product design and development process.
As the capabilities of intelligent products continue to grow, we argue that this toolkit needs to evolve to keep pace. The gap we perceive is how to account for the cognitive and emotional challenges when users engage with and try to interpret information they may need to act upon.
To some extent, a game of design catch-up has been playing out for decades. Every few years a new design method — and buzzword — emerged to help designers deal with new complexities.
In the early days of the web, designers were focused on how to organize and bucket information, which at that time was mostly static content. Information Architecture (IA) helped designers produce an information hierarchy and navigation scheme so users could locate and find what they needed.
Maturing around the web as a visual medium, user interface (UI) design draws on the long history of human-computer interface (HCI) research, applying a graphic language to affordances like buttons, menus and content panels. By establishing a visual hierarchy, it helped make important things visible while letting you find and get to what you might need.
As the world of installed applications began to intersect with the web, and as mobile apps emerged in the 2000s, designers and developers needed better ways to see how well their products could address user needs. As product complexity increased, user experience (UX) practice arose to construct a comprehensive picture of user needs, and characterize the tasks they are trying to accomplish. Drawing on extensive user research, UX practice introduced artifacts such as user personas, task analyses, empathy maps and workflow diagrams. Repeatable design patterns facilitated consistency around common interaction scenarios.
Where does that leave us now? A skilled product team, using common UX methods, can now pretty regularly wrap an effective experience around a basic set of workflows. They can organize information affordances, display insights via standard charting tools, engage a user via social features, and project an organization’s key brand attributes via their product.
But with intelligent products and complex nonlinear workflows, traditional experience design methods need to be extended. Consider the challenges faced by designers of a smart product like 23&me, which has the ability to display health insights based on a user’s DNA data, yet can easily frighten a user with risk factors for diseases like cancer, diabetes, Alzheimer’s as well as many more obscure hereditary conditions. Some users, if shown that they are at high risk for breast cancer, may decide to have a prophylactic mastectomy. A lot is at stake.
23&me’s product designers no doubt have to make difficult decisions about what and when to show users, and how to help them understand risk probabilities. To make decisions that involve interpretability, user anxiety and potential high-stakes decision-making, they could benefit from a toolkit that extends beyond traditional personas, customer journey maps, empathy maps and other current experience design artifacts.
Design patterns at the level of cognition
Where to go next? In this environment, we propose that what’s needed is a deeper cognitive understanding of our customer. That’s where it helps to bring in brain science to get a better picture of how people — customers and users, say— are likely to make choices and decisions based on data and information. This approach, which we refer to as Cognitive Workflow, can sometimes be counterintuitive:
- Whereas the product design practice generally strives to minimize user friction on the way to accomplishing a task, cognitive workflow can embrace selective friction as a tool to help a user learn more effectively. (1)
- Where typical workflows generally guide a user through a process to a pre-defined call-to-action (CTA) or a small set of potential endpoints, a cognitive workflow can feature unlimited endpoints. Which one is appropriate for a particular user scenario may depend on what conclusions they draw from insights along the way.
- Product design personas aim to capture a snapshot of a typical user, their personality and goals. A cognitive extension to persona-development would strive to characterize the decision-making style and cognition modes they are likely to apply on the way to achieving those goals. Is a particular persona, for example, more likely to make decisions analytically or by using intuition?
How does a cognitive approach help product teams contend with the complexity of smart products? A short answer is that it deploys design patterns at a higher level of abstraction.
While product design practice generally draws on established patterns for user actions such as navigation, drill down, shopping carts and interacting with video content, a cognitive approach extends this model to data-driven decisioning patterns like:
- How do I narrow down a large set of options to a manageable few?
- How can I evaluate something by comparing it to norms and benchmarks?
- How can I compare among a small number of options?
- How can I understand which elements of something are performing well and which are not?
- What is the likely outcome of an action I am contemplating?

Fig 3: A basic decisioning pattern for ‘How can I compare among a small number of options?’
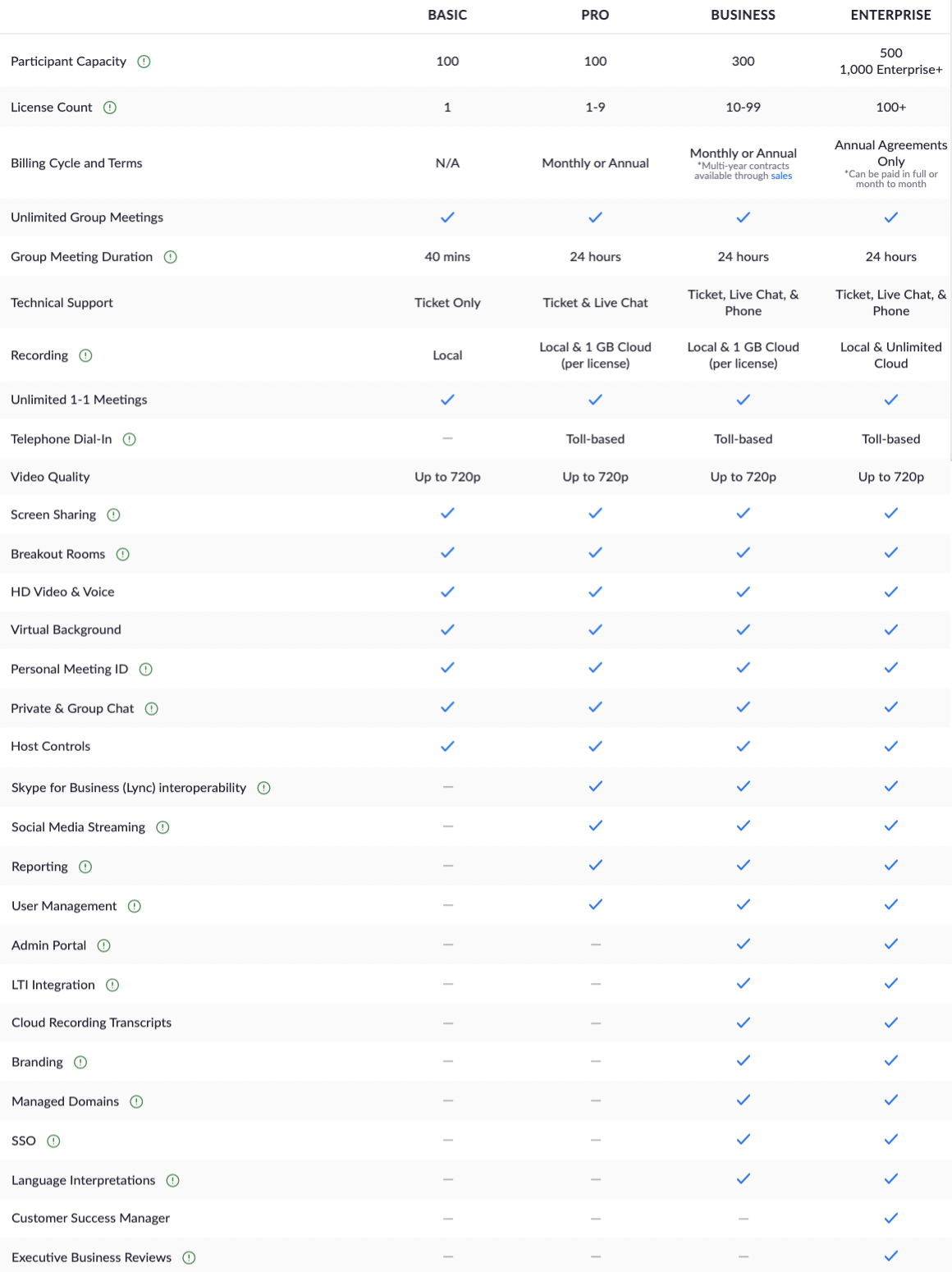
Fig 4: … and an example of it, from Zoom’s pricing comparison chart (adapted from https://zoom.us/pricing)
A valuable evolution of the product design practice, we propose, is a set of higher-order building blocks that can be used to assemble cognitively-beneficial experiences for a wide range of decision-making and problem-solving challenges.
(1) Cognitive psychologist Stanislas Dehaene, in his description of active engagement, one of his four pillars of successful learning, observes that ‘Making learning conditions (reasonably) more difficult will paradoxically lead to increased engagement and cognitive effort, which means improved attention.’ http://parisinnovationreview.com/articles-en/did-neuroscience-find-the-secrets-of-learning